
Research agenda
AI for Adjuvant Design
I study structured, knowledge-grounded AI for formalizing adjuvant research questions, evaluating scientific reasoning, and testing generated designs against literature evidence and mechanistic constraints.
About
Structured data modeling for scientific AI
I am a PhD candidate in Pattern Recognition and Intelligent Systems at the State Key Laboratory of Multimodal Artificial Intelligence Systems (MAIS), Institute of Automation, Chinese Academy of Sciences (CASIA), jointly trained with Zhongguancun Academy. I am advised by Prof. Cheng-Lin Liu.
My related work covers reliable and efficient multimodal models, embodied reasoning, scientific agents, and online handwriting recognition and generation. These projects share an emphasis on structured data modeling across perception, language, scientific knowledge, and action.
Research
Research agenda and methodological foundations
The three layers connect a central scientific problem with its methodological foundations and broader applications.
AI for Adjuvant Design
Formalizing adjuvant knowledge, benchmarking open-ended scientific reasoning, and verifying generated designs through literature-grounded mechanism chains.
Structured Multimodal Modeling
Reliable reasoning, spatial grounding, adaptive visual representations, token efficiency, and factuality alignment for multimodal systems.
Science, Action & Sequential Data
Scientific agents, materials and weather applications, embodied navigation, video understanding, and online Chinese handwriting.
Formalize
Represent adjuvant design principles and immune mechanisms.
Benchmark
Evaluate open-ended, multimodal scientific reasoning.
Verify
Check proposed designs against precedent, outcomes, and mechanisms.
Updates
Research milestones
- MR-ALIGN was accepted to ACL 2026 Findings, extending our work on factuality alignment for reasoning models.
- Data-constrained machine learning for materials science was accepted to Materials Genome Engineering Advances.
- MeteorPred, ChartAgent, and fine-grained VLM quantization were accepted to CVPR 2026.
- Our adjuvant benchmark was accepted to ICLR 2026, alongside work on adaptive patching; RANGER was accepted to ICRA 2026.
Selected work
Problem definition, benchmarking, and verification
The first two projects form a continuous research program in AI for adjuvant design.
AI for Adjuvant Design
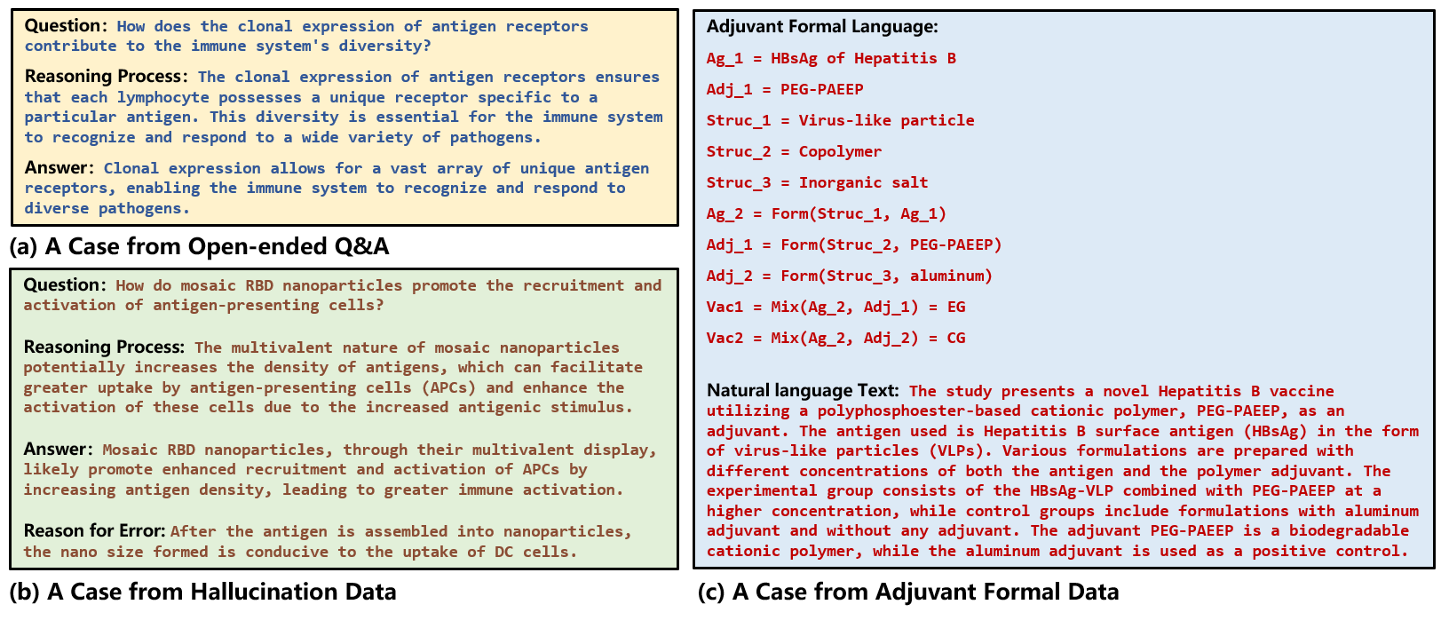
Problem definition & benchmarking
An Open-Ended Benchmark and Formal Framework for Adjuvant Research with MLLM
- Introduces an open-ended benchmark dedicated to multimodal adjuvant research.
- Formalizes adjuvant design principles and immune mechanisms for evaluation.
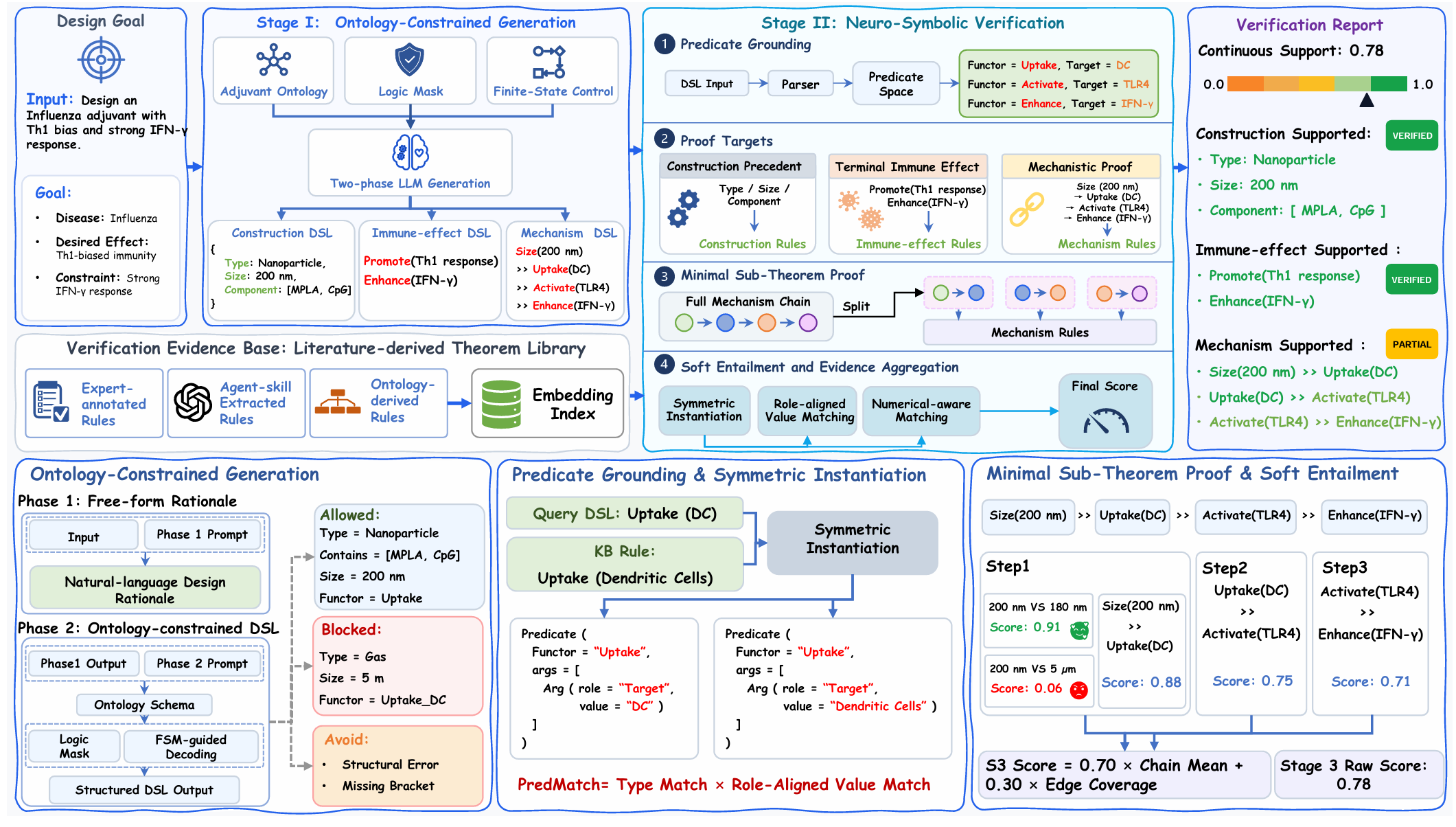
Design generation & verification
SAVANT: A Neuro-Symbolic Verification Framework for Adjuvant Design
- Frames adjuvant design verification as literature-grounded mechanistic proof checking.
- Checks precedent, immune outcomes, and mechanism chains while exposing evidence gaps.
Selected Technical Foundations
Topology-Aware Visual Prompts are Weakly Supervised Spatial Grounding Learners
Uses explicit referent-relation modeling and topology-aware prompting for weakly supervised spatial grounding.
Recoverable Compression: A Multimodal Vision Token Recovery Mechanism Guided by Text Information
Recovers task-relevant visual tokens with text guidance while compressing the visual token sequence.
Publications
Publications by research area
Select a research area to filter the list. * denotes equal contribution.
Order: newest year first; within each year, earlier Yi Chen author positions first.
Core research agenda
AI for Adjuvant Design
-
SAVANT: A Neuro-Symbolic Verification Framework for Adjuvant Design
Technical foundations
Structured Multimodal Modeling & Reasoning
- Topology-Aware Visual Prompts are Weakly Supervised Spatial Grounding Learners
- ElementCheck: Long-Form Text Factuality Evaluation via Sentence-Level Fact Elements
- BioChartBench: A Benchmark for Structured Quantitative Extraction from Biomedical Charts
- OpenFC: Learning Verification Policies for Open-Search Fact Checking
- Fine-Grained Post-Training Quantization for Large Vision Language Models with Integrated Gradients
Broader capabilities
Scientific, Embodied & Domain Work
- An Efficient Strategy for Data-Constrained Machine Learning in Materials Science
- CL-OCR: Fusing Layout Analysis and Adapting Recognition for Document Parsing in the Wild
- MapGPT: A Map-Centric Multimodal Model and Benchmark for Indoor Spatial Reasoning
Background
Education, recognition & service
Education
- PhD Candidate, Pattern Recognition and Intelligent SystemsMAIS, CASIA
- MS, Electronic InformationNLPR, CASIA
- Detection, Guidance and Control TechnologySchool of Space Science and Technology, Xidian University
Selected Honors
- 2026ICML Gold Reviewer
- 2025Academic Research Star, Zhongguancun Academy
- 2025Best Paper Award, AIHCIR
- 20243rd Place, ICDAR Multi-Font Group Recognition & OCR Competition
Academic Service
- JournalsIEEE TCSVT, TMLR
- Program committeeAAAI 2026, AAAI 2027
- Conference reviewerICLR 2026, CVPR 2026, ICML 2026, ECCV 2026
Open Source
PaddleScience contributor. Integrated Crystal Graph CNN for materials chemistry, including crystal data processing and graph-network training.
View merged PR #977